
Screen Shot 2026-03-30 at 4.51.32 AM.png
- 92.20 KB
(1132x839)


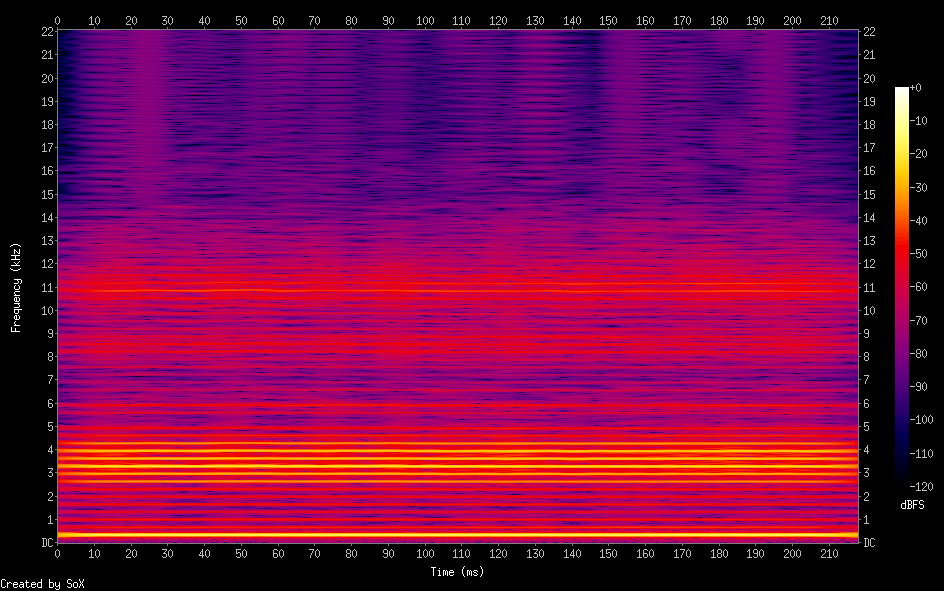
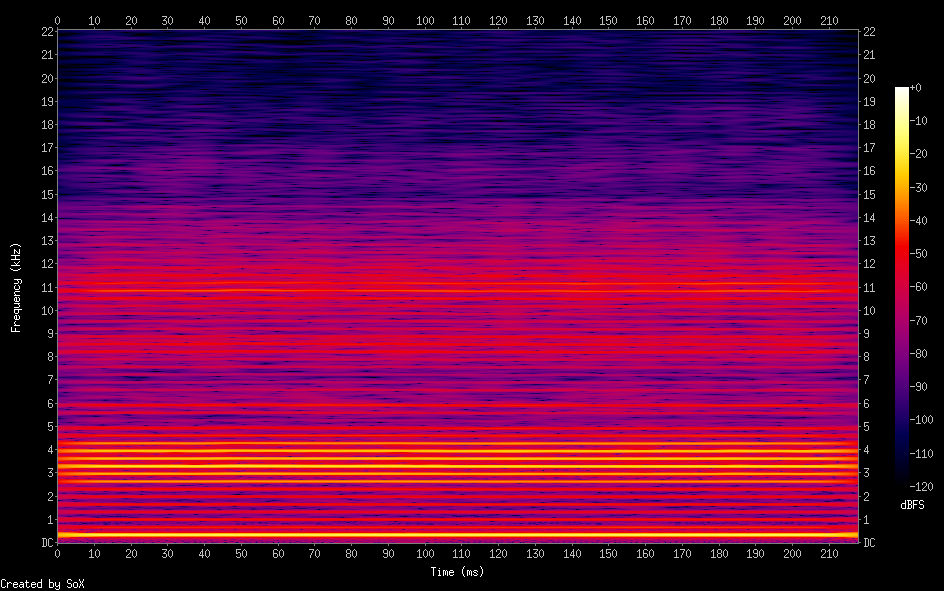
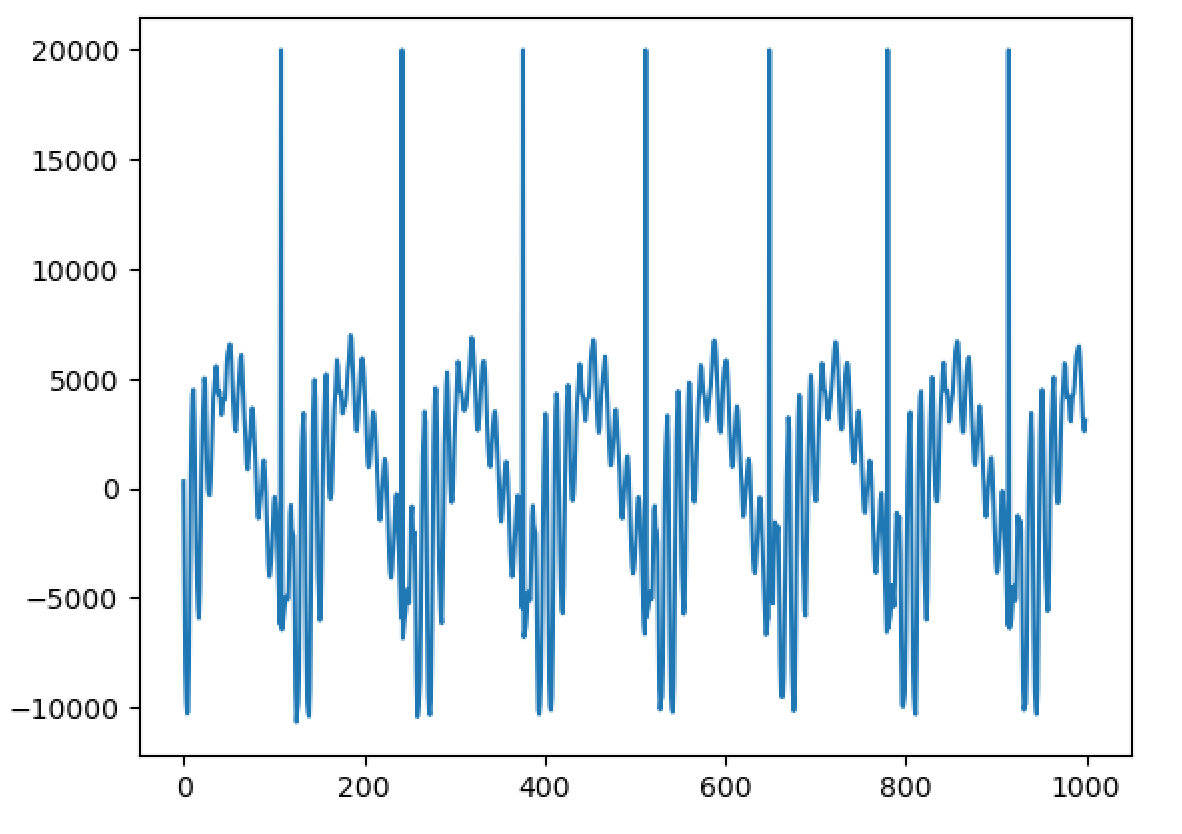
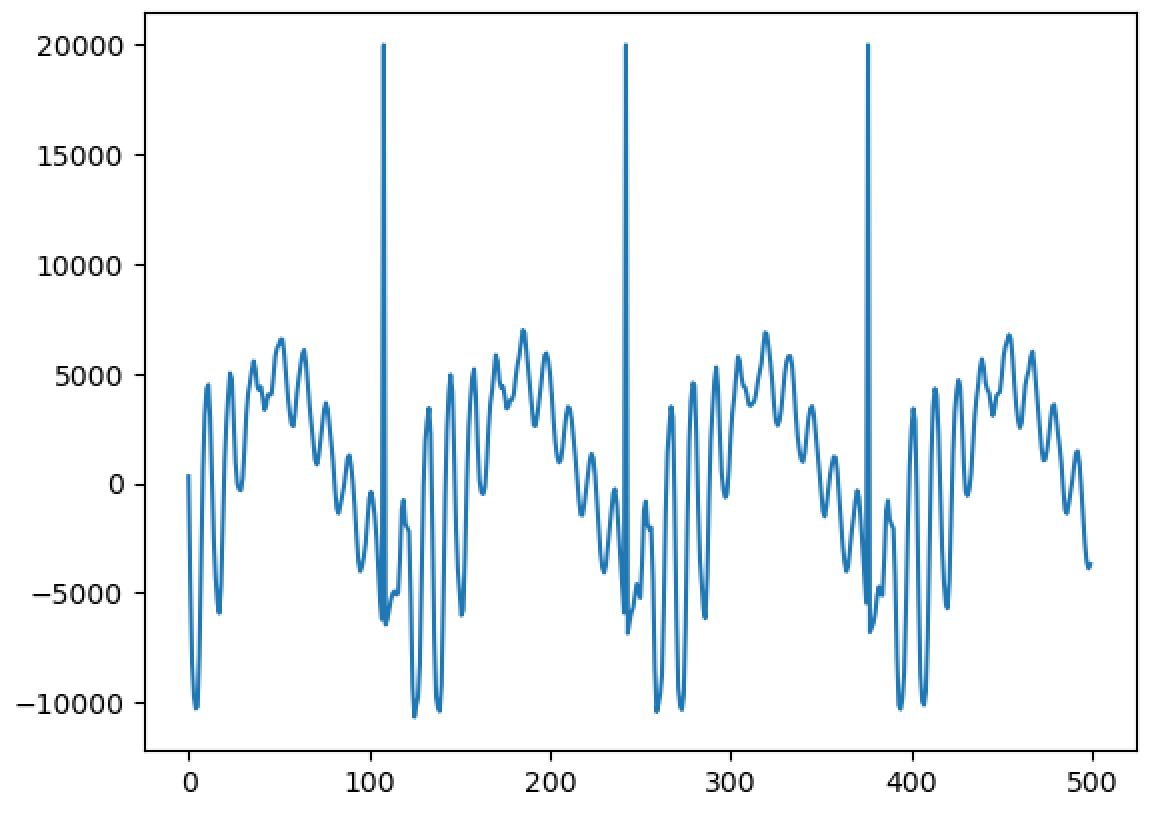
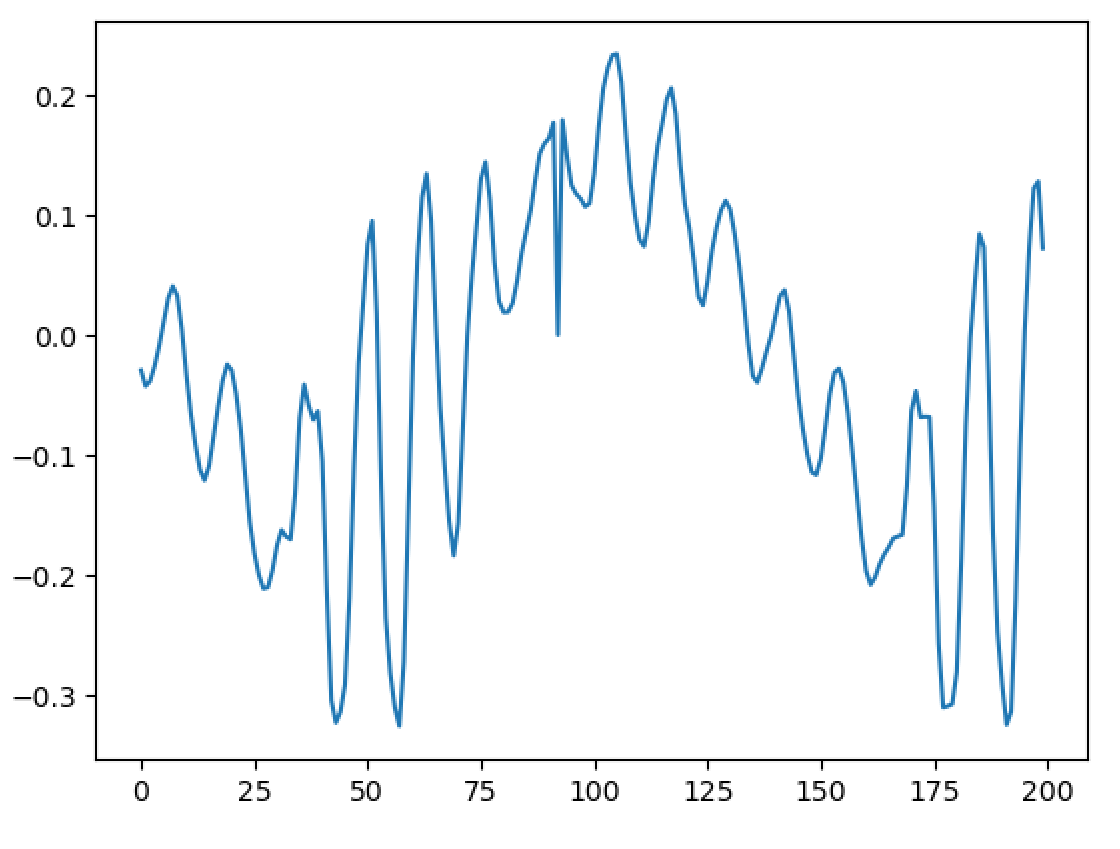
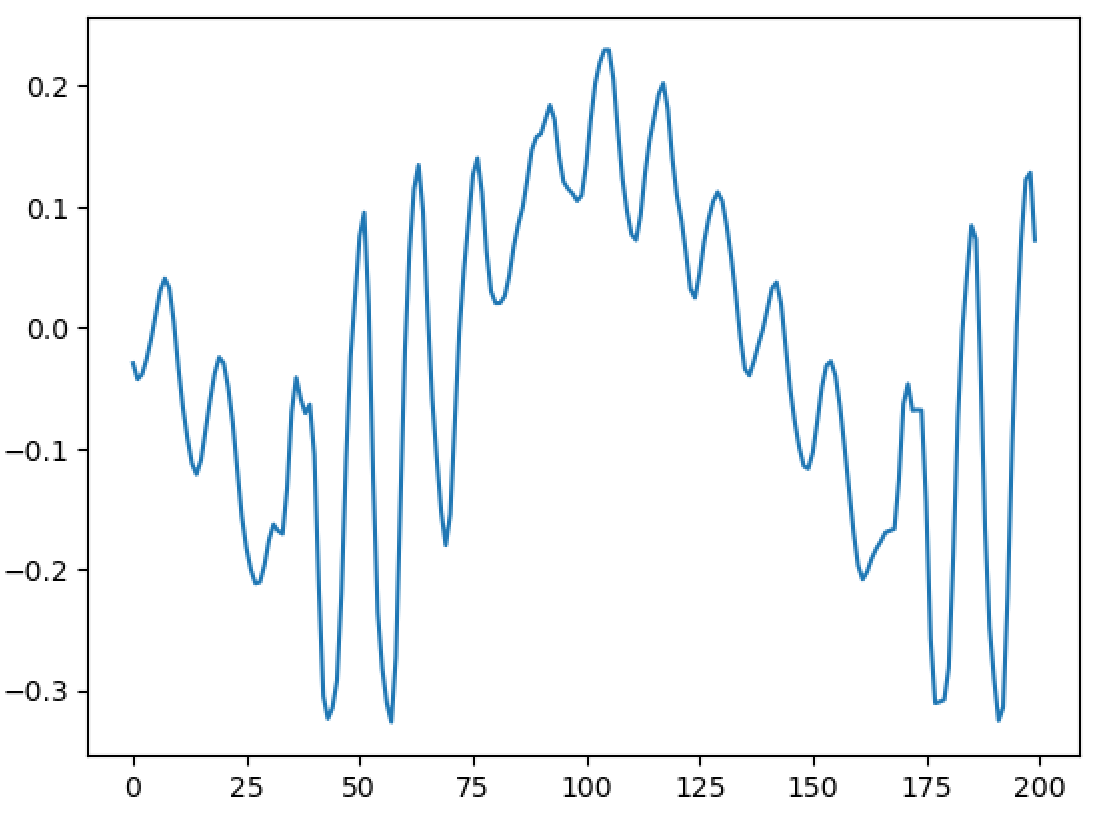
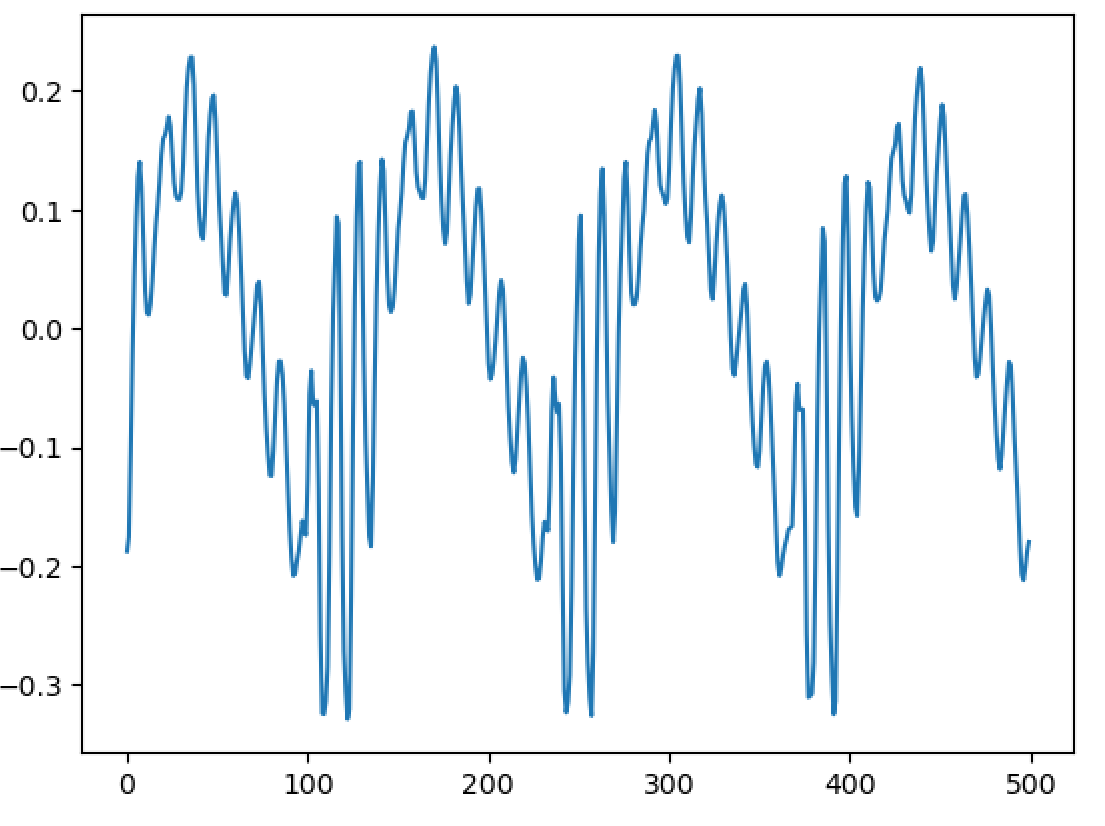
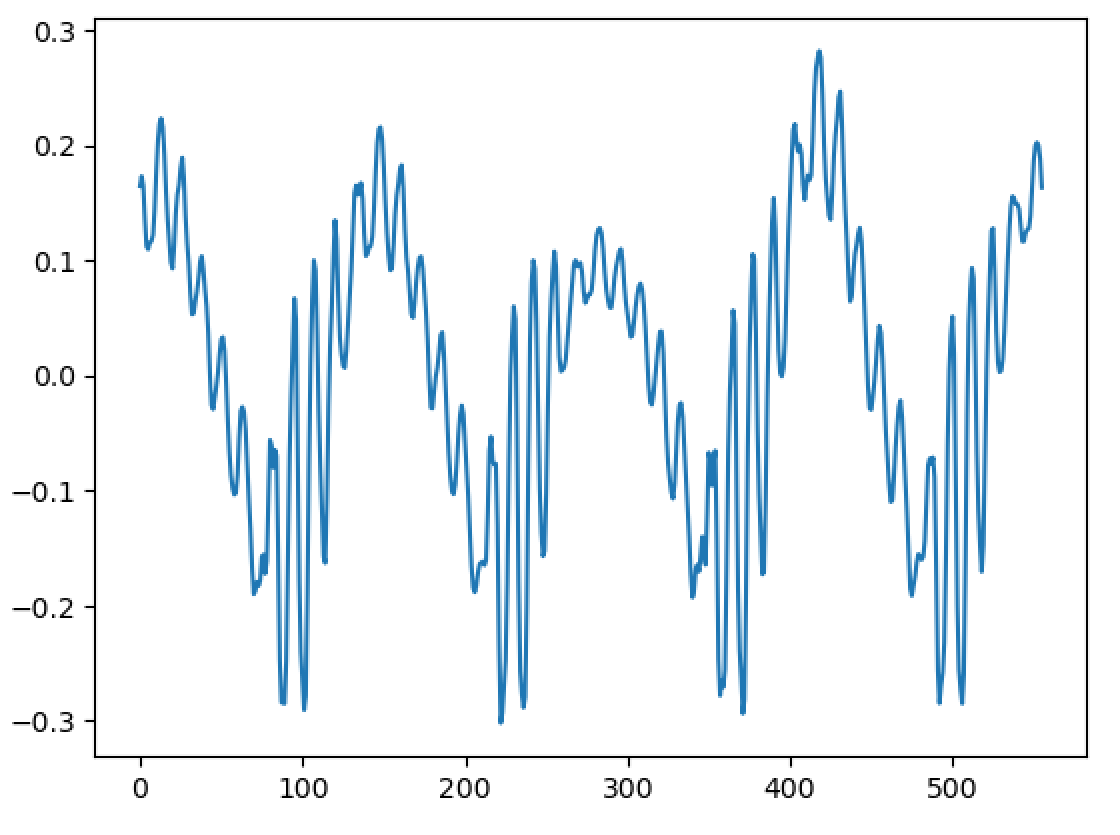
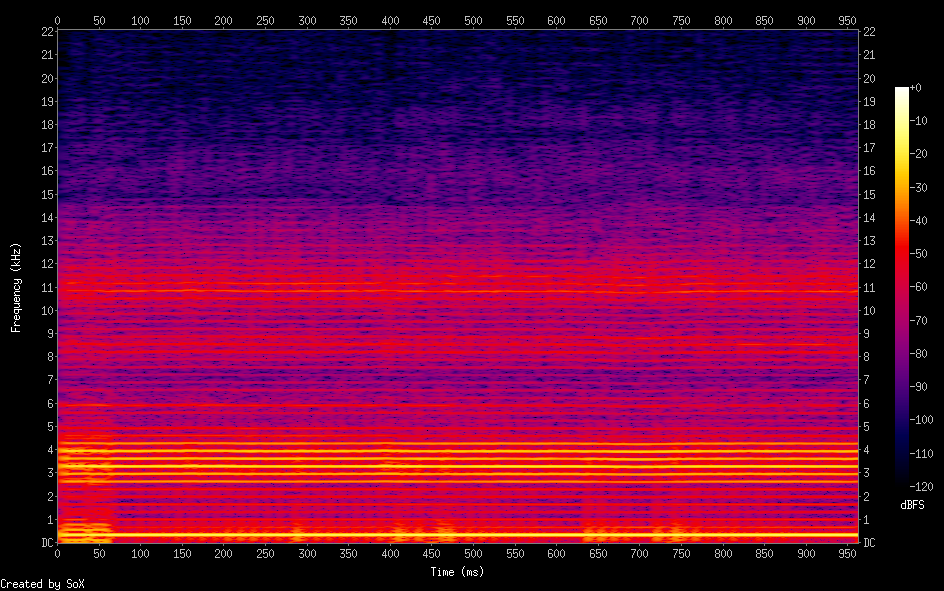
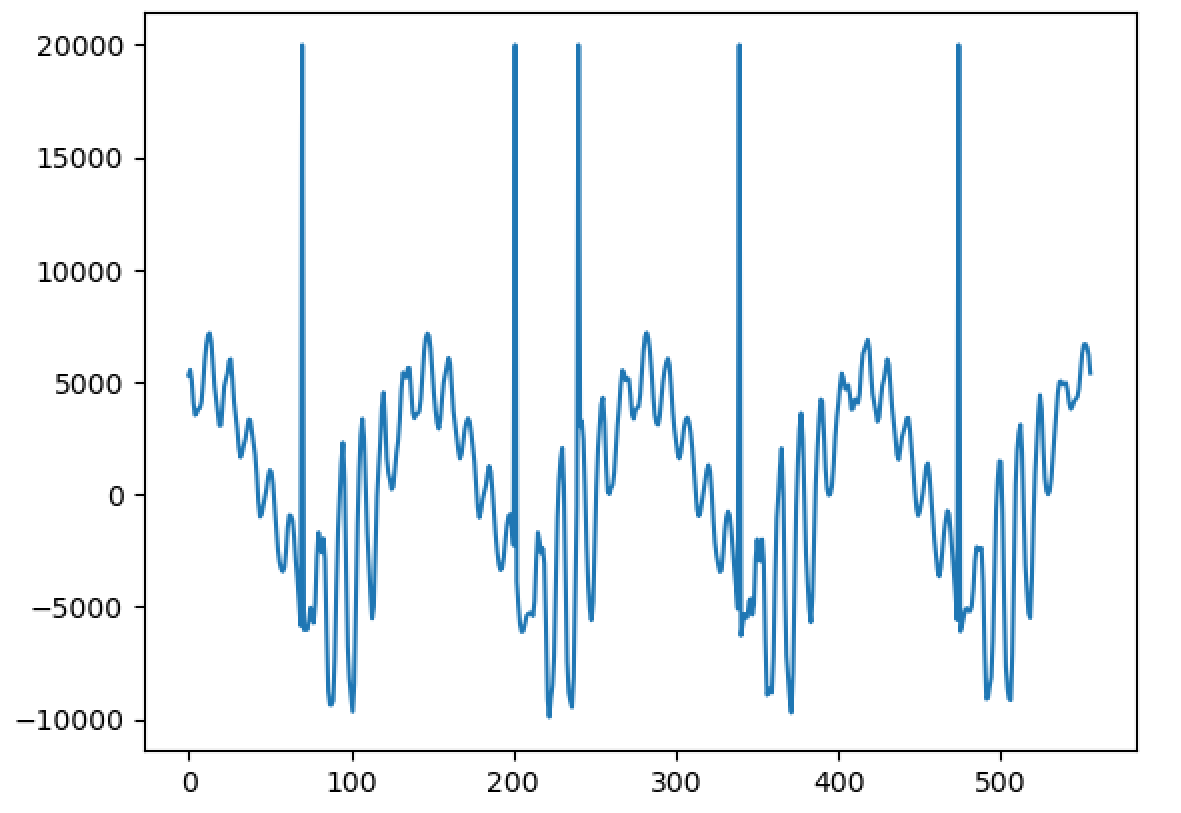
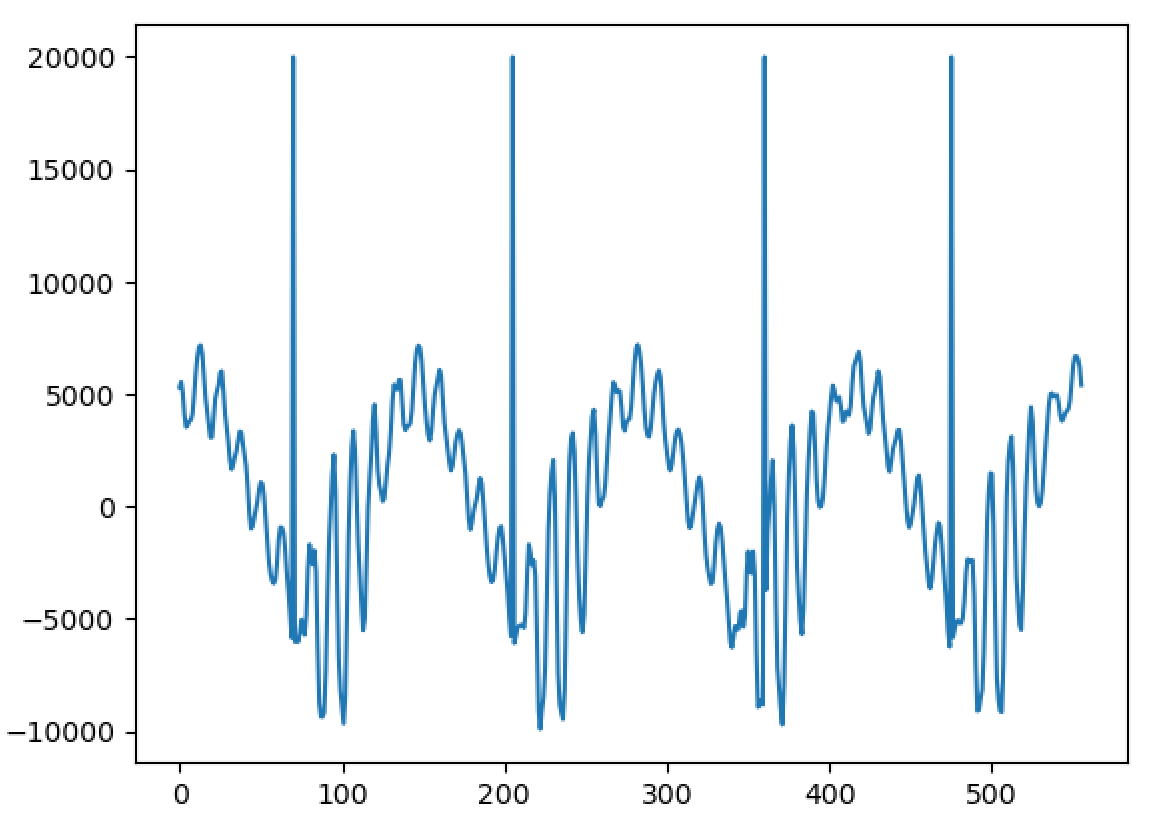
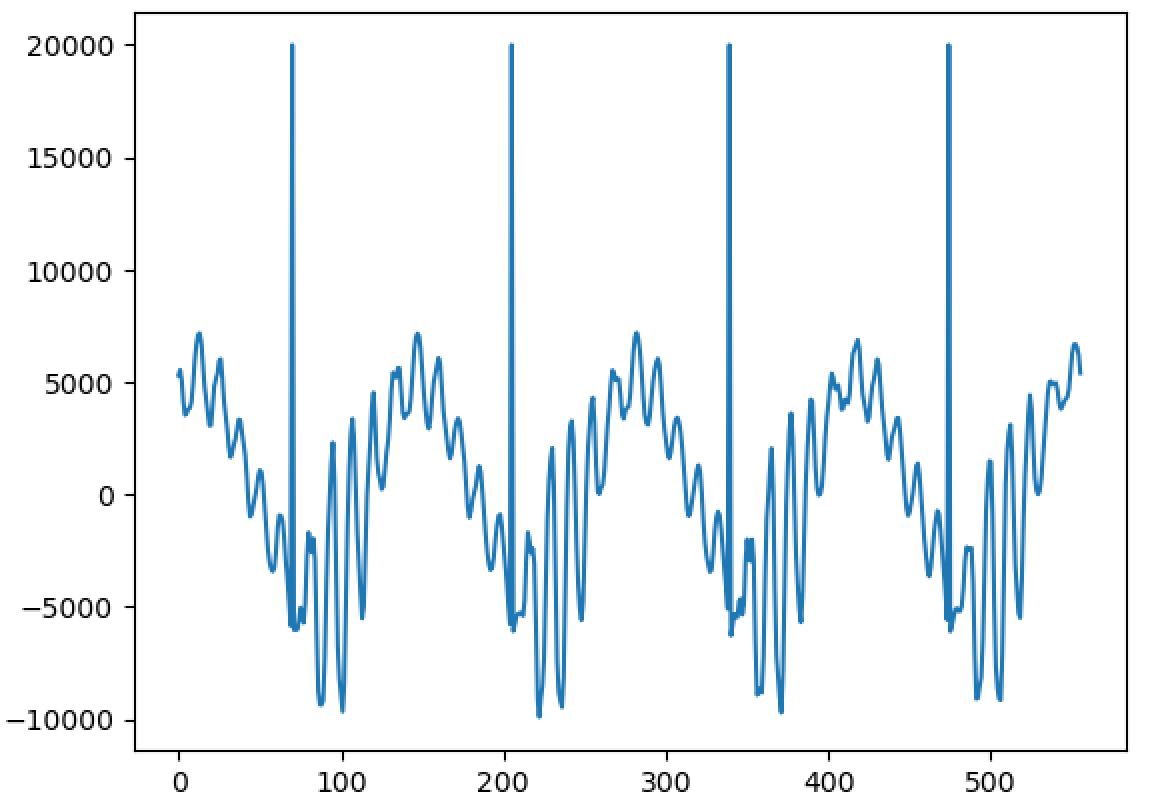
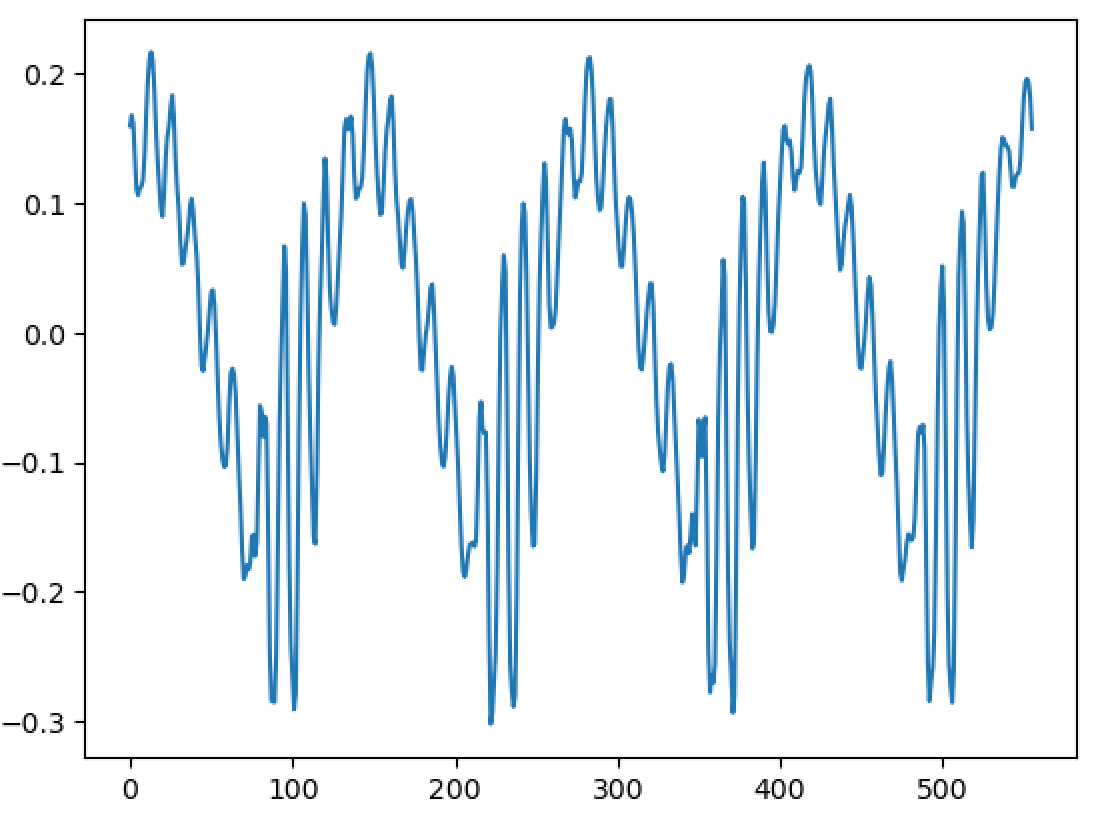
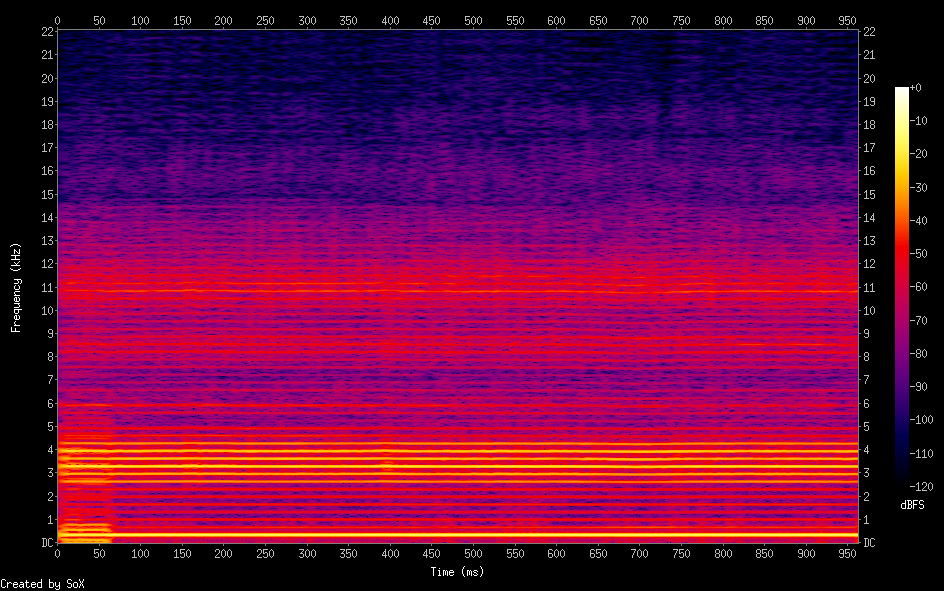
Hello, I'm back and I have a major update to my VOCALOID project! I have sucessfully achieved a shape-invariant pitch transposition! Here it is. First the original audio: https://files.catbox.moe/zmt3rr.wav Now my version with WBVPM (pitched down by an octave): https://voca.ro/1mJ5qljrp9hD or https://files.catbox.moe/kho97n.wav And a version using a naive pitch shift: https://files.catbox.moe/xs39bq.wav Notice that my version, while having more noise, sounds more natural and has less phasiness. This is particular noticeable if you play both at very low volume. One sounds much more 'human' than the other. Also note that this an extreme example with an octave shift (or 1200 cents) - in practice, shifts would typically be far less. Also this doesn't implement several other parts of the system (more on that later). I'll explain all of this in a moment, but first, I'd to correct some major biographical errors. Since this is a long post, I've divided it into sections BIOGRAPHICAL CORRECTIONS In the last post, I claimed that VOCALOID1 used Narrow-Band Voice Pulse Modeling while VOCALOID2 and onwards used Wide-Band Voice Pulse Modeling. This was incorrect, and additionally it was the source of most of my confusion surround the paper. What actually happened is that the research technology that would later become VOCALOID1 started out as work to improve the existing Spectral Modeling Synthesis system that had been developed in the early 1990s. This improvement began work in the late 1990s. But importantly, this system evolved and techniques from it were incorporated with techniques from a system that was being developed called a Phase-Locked Vocoder, and this system would be released as VOCALOID1. In the mid-2000s, work began on combining the techniques learned from improving SMS and the PLVC-based system and attempting to combine them with the mucher older and well-known TD-PSOLA system. Importantly, TD-PSOLA (Time-Domain Pitch Synchronous OverLap and Add) was a time-domain system, while SMS was a frequency-domain system (and also TD-PSOLA was pitch synchronous - hence the name, while SMS had a constant hop size). The first technique they developed was Narrow-Band Voice Pulse Modeling, and later Wide-Band Voice Pulse Modeling. Wide-Band Voice Pulse Modeling ended it up being used in VOCALOID2. Now that I understand this, I also understand the major mistake I made when reading the paper: I was reading it from the perspective of an implementer, thinking of the sections as the steps to implementing it instead of as research. I had thought that section 2.2 described the core processing algorithms. When it was actually about SMS, and importantly, about *the improvements they made to SMS*, and not a complete description of SMS, since SMS was already an established technique. Hence my confusion on why some things were seemingly vaguely explained, since *the paper wasn't about them*. At the same time, much of that section is very useful though because importantly, much of that research was also incorporated into the later techniques. RESULTS I have successfully implemented the Wide-Band Voice Pulse Modeling; synthesis; and pitch transposition, time stretching, and timbre scaling algorithms. Additionally, I have also finished implementing the full version of the pitch estimation module, changed the code to work using overlapping windows, implemented the window adaption system, and fixed countless.
{kind=link}
{kind=link}
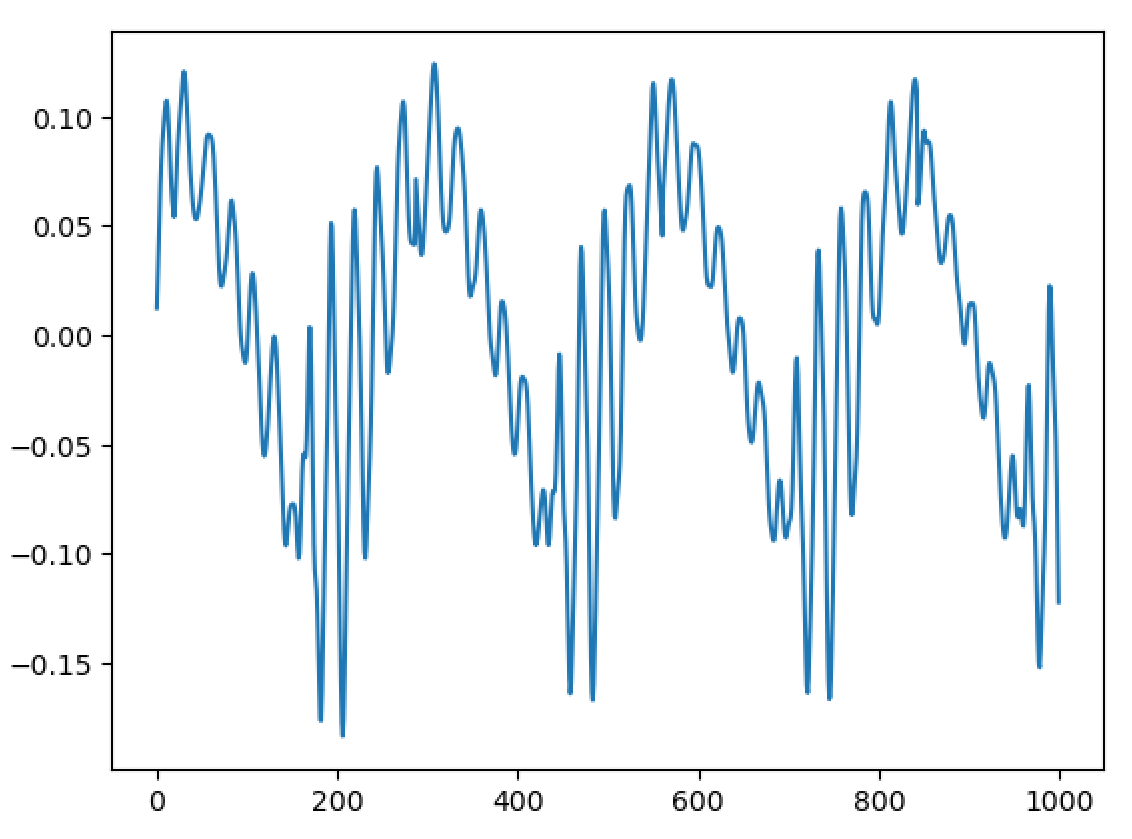{kind=link}
{kind=link}
{kind=link}
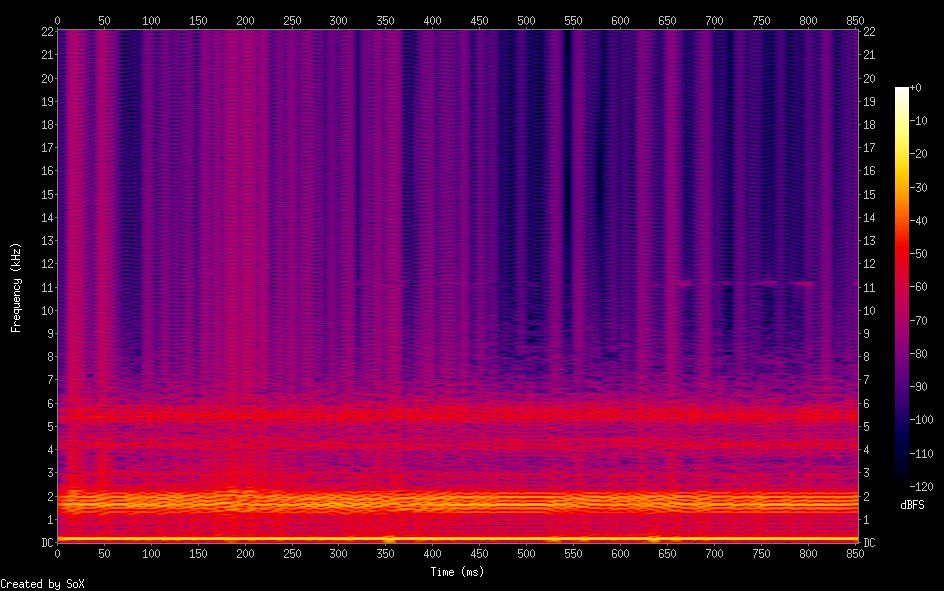{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}